MCEBuddy puede convertir automáticamente subtítulos basados en imágenes (por ejemplo, subtítulos DVB o incrustados) en subtítulos de texto (SRT) utilizando OCR (Reconocimiento Óptico de Caracteres). Esta función requiere descargar archivos adicionales, ya que el procesamiento OCR necesita archivos de datos muy grandes (~1 GB de tamaño) que no se pueden incluir en el instalador de MCEBuddy.
MCEBuddy Versión 2.7.1 y posteriores
Los archivos OCR se descargan e instalan automáticamente si hay una conexión a Internet disponible después de completar la instalación de MCEBuddy.
MCEBuddy Versión 2.6.2 a 2.6.6
Durante la instalación, la opción de descargar e instalar automáticamente los archivos complementarios OCR necesarios está habilitada por defecto. Puedes deshabilitarla si no deseas que se descarguen e instalen automáticamente los archivos complementarios OCR.
Si la descarga falló debido a la falta de conexión a Internet o no seleccionaste la instalación automática durante la configuración, puedes activar en cualquier momento una reinstalación automática de los archivos complementarios OCR haciendo clic en el enlace Install OCR add-on en la página Conversion task, como se muestra a continuación:
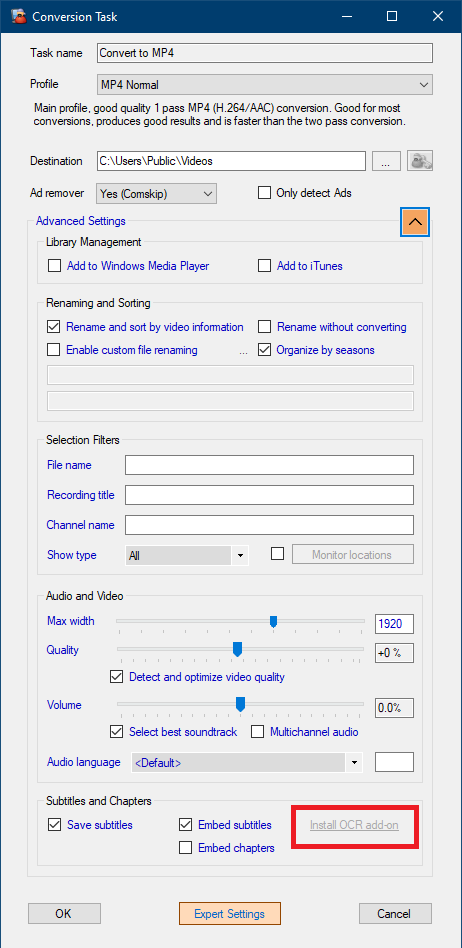
InstallOCR add-onen gris significa que los archivos complementarios han sido instalados. Haz clic en el texto para volver a descargarlos y reinstalarlos (~500 MB de descarga)
Install OCR add-onen rojo significa que los archivos complementarios aún no han sido instalados. Haz clic en el texto para descargarlos e instalarlos (~500 MB de descarga)
Asegúrate de que las opciones Save subtitles o Embed subtitles estén habilitadas en Conversion task → Advanced settings para extraer y procesar subtítulos usando OCR.
MCEBuddy Versiones 2.4.7 a 2.6.1
Necesitarás descargar e instalar manualmente los archivos OCR como se describe a continuación.
Sigue el siguiente procedimiento para habilitar OCR y la conversión de subtítulos de imagen a texto para extraer subtítulos DVB y otros subtítulos basados en imágenes de las grabaciones.
- Descarga los archivos OCR desde https://github.com/tesseract-ocr/tessdata/archive/3.04.00.zip
- Extrae el contenido del archivo zip (
tessdata-3.04.00.zip). Debería crear una carpeta llamadatessdata-3.04.00dentro de la cual habrá más de 100 archivos traineddata. Asegúrate de que no haya subcarpetas. Debería verse así:tessdata-3.04.00\\<100+ archivos traineddata>- Mueve la carpeta
tessdata-3.04.00al directorio ccextractor donde está instalado MCEBuddy: \<directorio de instalación de MCEBuddy>\ccextractor\
por ejemplo, muevetessdata-3.04.00dentro deC:\\Program Files\\MCEBuddy2x\\ccextractor\\- Renombra el directorio
tessdata-3.04.00atessdata. Importante: No te saltes este paso o el OCR no funcionaráAsí que tu configuración final debería verse así: \<directorio de instalación de MCEBuddy>\ccextractor\tessdata\<100+ archivos traineddata>
por ejemplo,C:\\Program Files\\MCEBuddy2x\\ccextractor\\tessdata\\<100+ archivos traineddata>
¡Asegúrate de haber habilitado la opción Extract subtitles and closed captions en la configuración avanzada de tu tarea de conversión y estás listo! Extraerá y convertirá subtítulos basados en imágenes en un archivo SRT de texto. ¡Disfrútalo!
Las versiones anteriores a la 2.4.7 no admiten OCR