MCEBuddy can automatically convert image based subtitles (e.g. DVB or burned in subtitles) into a text subtitle (SRT) using OCR (Optical Character Recognition). This feature requires additional files to be downloaded because OCR processing requires very large data files (~1 GB in size) which cannot be bundled within the MCEBuddy setup file.
MCEBuddy Version 2.7.1 and newer
The OCR files are automatically downloaded and installed if an internet connection is available after MCEBuddy setup completes.
MCEBuddy Version 2.6.2 to 2.6.6
During installation the option to automatically download and install the required OCR add-on files is enabled by default. You can disable it if do not want the OCR add-on files downloaded and installed automatically.
If the download failed due to lack of an internet connection or you did not select the automatic installation during setup, you can at anytime trigger an automatic re-install of the OCR add-on files by clicking on the Install OCR add-on link in the Conversion task page as shown below:
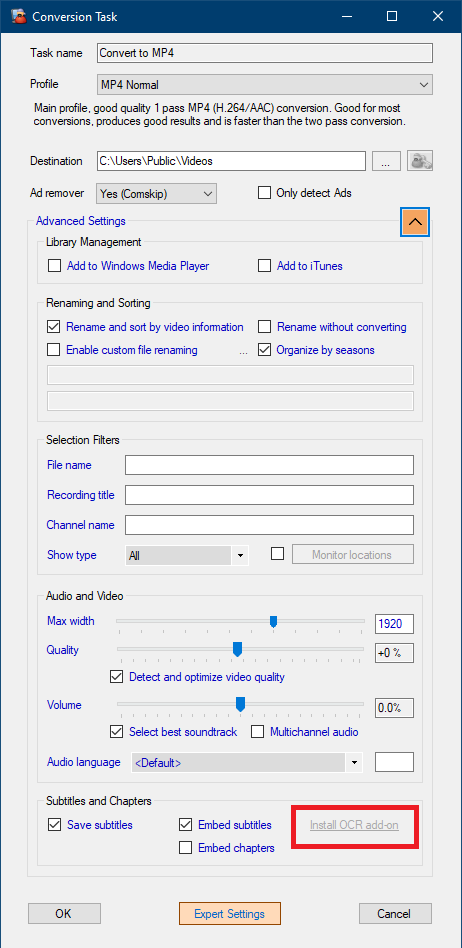
InstallOCR add-onin grey means that the add-on files have been installed. Click on the text to redownload and reinstall them (~500MB download)
Install OCR add-onin red means that the add-on files have not yet been installed. Click on the text to download & install them (~500MB download)
Make sure that Save subtitles or Embed subtitles options are enabled in the Conversion task → Advanced settings to extract and process subtitles using OCR.
MCEBuddy Versions 2.4.7 to 2.6.1
You will need to manually download and install the OCR files as described below.
Follow the below procedure to enable OCR and image to text subtitle conversion to extract DVB and other image based subtitles from recordings.
- Download the OCR files from https://github.com/tesseract-ocr/tessdata/archive/3.04.00.zip
- Extract the contents of the zip file (
tessdata-3.04.00.zip). It should create a folder calledtessdata-3.04.00inside which will be 100+ traineddata files. Make sure there are no sub-folders. It should look liketessdata-3.04.00\<100+ traineddata files>- Move the folder
tessdata-3.04.00to inside the ccextractor directory where MCEBuddy is installed: <MCEBuddy installation directory>\ccextractor\
e.g. Movetessdata-3.04.00to insideC:\Program Files\MCEBuddy2x\ccextractor\- Rename the
tessdata-3.04.00directory totessdata. Important: Do not miss this step or OCR wont’ workSo your final setup should look like: <MCEBuddy installation directory>\ccextractor\tessdata\<100+ traineddata files>
e.g.C:\Program Files\MCEBuddy2x\ccextractor\tessdata\<100+ traineddata files>
Make sure you’ve enabled the Extract subtitles and closed captions option in your Conversion Task advanced settings and you’re all set! It will extract and convert image based subtitles into a text SRT file. Enjoy!
Versions older than 2.4.7 do not support OCR
