MCEBuddy kan op basis van afbeeldingen gemaakte ondertitels (zoals DVB of ingebrande ondertitels) automatisch omzetten naar een tekstondertitel (SRT) met behulp van OCR (Optical Character Recognition). Deze functie vereist dat aanvullende bestanden worden gedownload, omdat OCR-verwerking zeer grote gegevensbestanden vereist (~1 GB groot) die niet in het MCEBuddy-installatiebestand kunnen worden gebundeld.
MCEBuddy Versie 2.7.1 en nieuwer
De OCR-bestanden worden automatisch gedownload en geïnstalleerd als er een internetverbinding beschikbaar is nadat de MCEBuddy-installatie is voltooid.
MCEBuddy Versie 2.6.2 tot 2.6.6: Tijdens de installatie is de optie om de vereiste OCR-add-onbestanden automatisch te downloaden en te installeren standaard ingeschakeld. U kunt deze uitschakelen als u niet wilt dat de OCR-add-onbestanden automatisch worden gedownload en geïnstalleerd.
Als het downloaden is mislukt vanwege een gebrek aan internetverbinding of als u de automatische installatie tijdens de installatie niet hebt geselecteerd, kunt u op elk moment een automatische herinstallatie van de OCR-add-onbestanden activeren door op de koppeling Install OCR add-on te klikken op de pagina Conversietaak, zoals hieronder wordt weergegeven:
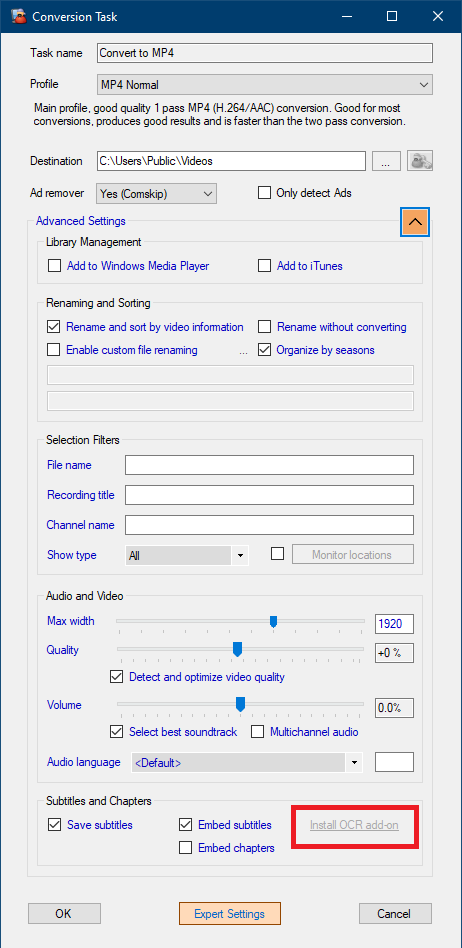
InstallOCR add-onin grijs betekent dat de add-onbestanden zijn geïnstalleerd. Klik op de tekst om ze opnieuw te downloaden en te installeren (~500MB download)
Install OCR add-onin rood betekent dat de add-onbestanden nog niet zijn geïnstalleerd. Klik op de tekst om ze te downloaden en te installeren (~500MB download)
Zorg ervoor dat de opties Ondertitels opslaan of Ondertitels insluiten zijn ingeschakeld in de Conversietaak → Geavanceerde instellingen om ondertitels met OCR te extraheren en te verwerken.
MCEBuddy Versies 2.4.7 tot 2.6.1
U moet de OCR-bestanden handmatig downloaden en installeren zoals hieronder beschreven.
Volg de onderstaande procedure om OCR en de conversie van afbeelding naar tekstondertitel in te schakelen om DVB- en andere op afbeeldingen gebaseerde ondertitels uit opnames te extraheren.
- Download de OCR-bestanden van https://github.com/tesseract-ocr/tessdata/archive/3.04.00.zip
- Pak de inhoud van het zip-bestand (
tessdata-3.04.00.zip) uit. Dit zou een map met de naamtessdata-3.04.00moeten aanmaken, met daarin meer dan 100 getrainde bestanden. Zorg ervoor dat er geen submappen zijn. Het zou eruit moeten zien alstessdata-3.04.00\<meer dan 100 getrainde bestanden>- Verplaats de map
tessdata-3.04.00naar de ccextractor-map waar MCEBuddy is geïnstalleerd: <MCEBuddy installatiemap>\ccextractor\\- Hernoem de map
tessdata-3.04.00naartessdata. Belangrijk: Sla deze stap niet over anders werkt OCR nietDus uw uiteindelijke configuratie zou er als volgt uit moeten zien: <MCEBuddy installatiemap>\ccextractor\tessdata\<meer dan 100 getrainde bestanden>
Bijv.C:\Program Files\MCEBuddy2x\ccextractor\tessdata\<meer dan 100 getrainde bestanden>
Zorg ervoor dat u de optie Ondertitels en gesloten bijschriften extraheren hebt ingeschakeld in de geavanceerde instellingen van uw Conversietaak en dan bent u klaar! Het zal op afbeeldingen gebaseerde ondertitels extraheren en converteren naar een SRT-tekstbestand. Veel plezier!
Versies ouder dan 2.4.7 ondersteunen geen OCR